
Một bước tiến đáng chú ý trong lĩnh vực trí tuệ nhân tạo và thiết bị đeo vừa được công bố bởi các nhà khoa học tại Đại học Khoa học và Công nghệ Pohang (POSTECH).
Nghiên cứu do Giáo sư Park Sung-Min và Tiến sĩ Hong Sun-Guk dẫn dắt, đăng tải trên tạp chí Cyborg and Bionic Systems, đã giới thiệu một hệ thống có khả năng chuyển đổi “lời nói thầm”, thậm chí là ý định nói, thành giọng nói nghe được.
Cách AI “đọc” chuyển động cơ cổ để tái tạo giọng nói
Trọng tâm của công nghệ này nằm ở việc tái định nghĩa khái niệm “lời nói”.
Theo nhóm nghiên cứu, lời nói không chỉ là âm thanh phát ra từ dây thanh quản, mà còn là chuỗi chuyển động cơ học phức tạp diễn ra ở vùng cổ họng. Ngay cả khi không phát ra âm thanh, các cơ nhỏ vẫn co giãn, tạo ra những biến dạng rất nhỏ trên bề mặt da, một dạng “dấu vết vô hình” của ngôn ngữ.
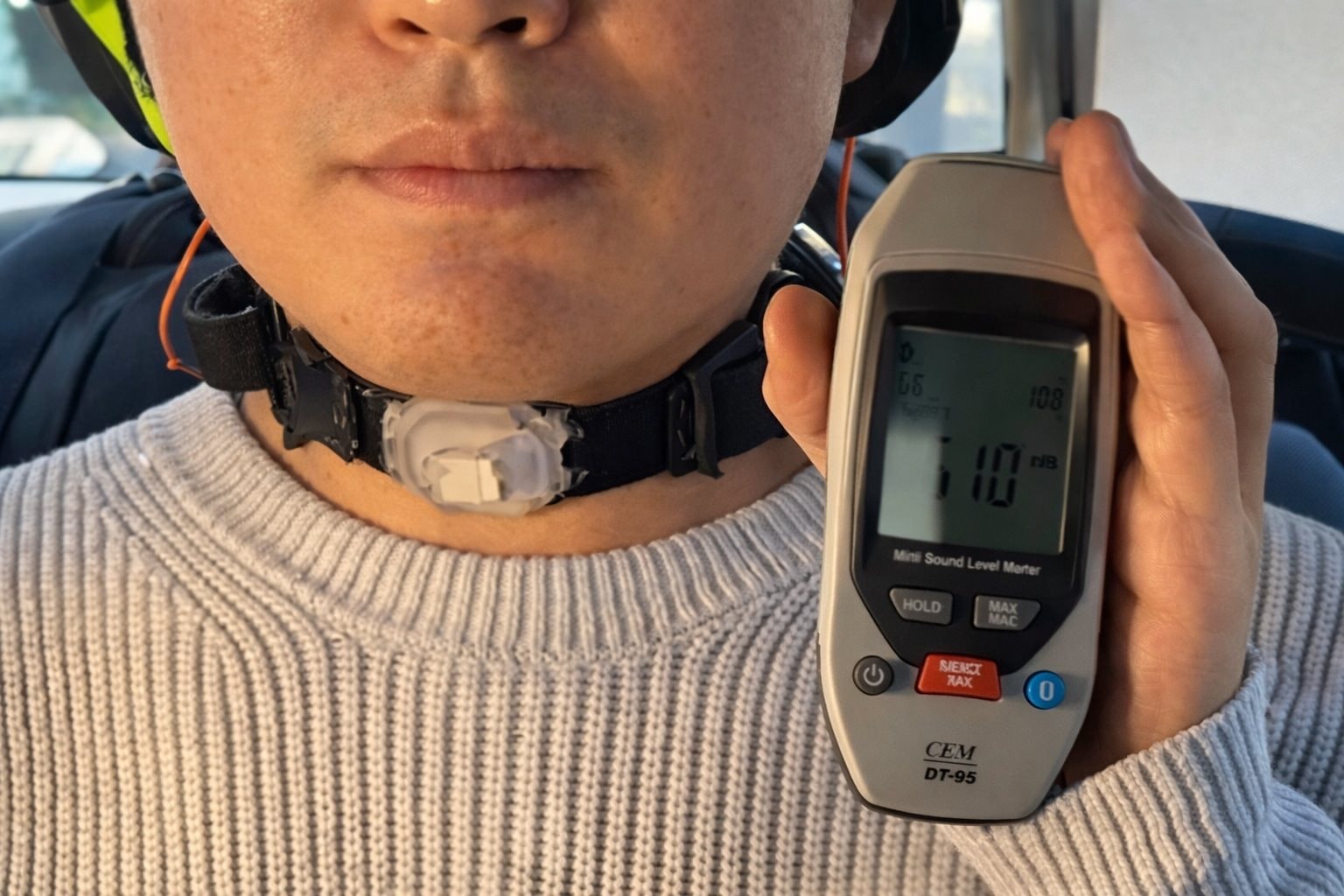
Để ghi nhận những tín hiệu này, nhóm đã phát triển một thiết bị đeo cổ sử dụng cảm biến lập bản đồ biến dạng đa trục. Thiết bị được cấu thành từ lớp silicone mềm tích hợp các điểm đánh dấu vi mô màu đen, kết hợp với camera thu nhỏ, ống kính hiển vi và hệ thống chiếu sáng LED.
Khi người dùng “nói thầm”, hệ thống sẽ theo dõi sự dịch chuyển của các điểm đánh dấu này để dựng lại bản đồ biến dạng của da và cơ cổ theo nhiều hướng khác nhau.
Khác với các cảm biến truyền thống chỉ ghi nhận chuyển động theo một trục, hệ thống này có thể đo đồng thời cả hướng và độ lớn của biến dạng. Nhờ đó, nó tái hiện đầy đủ hơn các chuyển động sinh học phức tạp liên quan đến quá trình phát âm.
Các thông số kỹ thuật cho thấy độ nhạy ấn tượng: Cảm biến phát hiện được biến dạng nhỏ tới 0,02%, hệ số đo biến dạng đạt 3,625, độ tuyến tính vượt 0,99 và độ trễ dưới 0,65%. Thiết bị cũng cho thấy độ bền cao khi duy trì ổn định qua hàng nghìn chu kỳ sử dụng.
Sau khi thu thập dữ liệu, hệ thống AI sẽ xử lý thông tin bằng mô hình lai giữa mạng nơ-ron tích chập (CNN) và Transformer. CNN đảm nhiệm việc trích xuất đặc trưng cục bộ từ bản đồ biến dạng, trong khi Transformer phân tích chuỗi tín hiệu theo thời gian, yếu tố quan trọng trong việc hiểu ngữ điệu và cấu trúc lời nói.
Một thách thức thực tế được giải quyết là sự thay đổi vị trí khi đeo thiết bị. Mỗi lần sử dụng, độ chặt và vị trí tiếp xúc có thể khác nhau, làm biến đổi tín hiệu. Để khắc phục, hệ thống đo “ứng suất dư ban đầu” nhằm hiệu chỉnh dữ liệu, đảm bảo AI không nhầm lẫn giữa biến dạng do đeo thiết bị và biến dạng do lời nói.
Kết quả là một chuỗi xử lý hoàn chỉnh: Từ chuyển động cơ học, dữ liệu số, giải mã AI đến tổng hợp giọng nói. Người dùng có thể “nói” mà không phát ra âm thanh, nhưng vẫn được nghe lại bằng chính giọng nói của mình.
Mở lối cho y học và giao tiếp thầm lặng
Hệ thống được huấn luyện trên 5.186 mẫu dữ liệu thu thập từ 6 người tham gia, sử dụng bộ từ vựng gồm 26 từ trong bảng chữ cái ngữ âm NATO (Alpha, Bravo, Charlie…). Đây là tập từ được thiết kế đặc biệt để đảm bảo rõ ràng trong môi trường nhiễu cao.

Trong thử nghiệm, mô hình đạt độ chính xác 85,8%. Sau khi tối ưu hóa bằng kỹ thuật chưng cất tri thức, kích thước mô hình giảm từ 12,4 MB xuống còn 3,6 MB, tốc độ xử lý tăng lên đáng kể (từ 0,018 giây xuống 0,003 giây), trong khi độ chính xác vẫn duy trì khoảng 82%.
Đáng chú ý, hệ thống cho thấy khả năng hoạt động ổn định trong môi trường cực kỳ ồn ào. Với mức nhiễu 90 decibel, tương đương tiếng ồn công trường, hiệu suất nhận diện gần như không suy giảm so với môi trường bình thường 60 decibel. Tỷ lệ tín hiệu trên nhiễu đạt 33,75 dB, cao hơn nhiều so với khoảng 10,17 dB của các hệ thống Điện cơ đồ thương mại.
Trong một thử nghiệm thực tế, thiết bị vẫn hoạt động khi người dùng sử dụng súng trường nén khí ở cả chế độ bán tự động và tự động hoàn toàn, cho thấy khả năng chống nhiễu cơ học đáng kể.
So với các phương pháp truyền thống như điện não đồ và đo điện cơ (EMG), vốn yêu cầu thiết bị cồng kềnh, điện cực hoặc môi trường kiểm soát, giải pháp mới mang tính ứng dụng cao hơn nhờ thiết kế gọn nhẹ, linh hoạt và dễ đeo.
Về mặt ứng dụng, công nghệ mở ra nhiều triển vọng đáng chú ý. Trong y học, những bệnh nhân mất giọng do tổn thương dây thanh quản hoặc phẫu thuật vẫn có thể tạo ra chuyển động cơ cổ. Hệ thống có thể tận dụng tín hiệu này để tái tạo lời nói, giúp họ khôi phục khả năng giao tiếp.
Trong môi trường công nghiệp, nơi tiếng ồn làm gián đoạn giao tiếp, thiết bị có thể thay thế micro truyền thống. Ngoài ra, công nghệ còn cho phép giao tiếp im lặng trong các không gian cần yên tĩnh như thư viện, phòng họp hoặc môi trường làm việc đặc thù.
Tuy vậy, nghiên cứu cũng chỉ ra một số hạn chế. Hiệu suất giảm khi thiết bị đeo không ổn định, khi người dùng cử động mạnh hoặc khi chuyển động đầu theo phương lên xuống. Việc nói quá lớn cũng có thể làm giảm độ chính xác do vượt quá giới hạn phần cứng hiện tại.
Nhóm nghiên cứu cho biết các bước tiếp theo sẽ tập trung vào mở rộng dữ liệu huấn luyện, tăng vốn từ vựng, cải thiện khả năng chống nhiễu do chuyển động và tối ưu hóa để tích hợp vào thiết bị tiêu dùng.
Dù còn trong giai đoạn phát triển, công nghệ này đã cho thấy một hướng đi mới trong giao tiếp người và máy: Không cần âm thanh, không cần micro, chỉ cần tín hiệu sinh học. Trong tương lai, những “lời nói chưa kịp cất thành tiếng” hoàn toàn có thể được AI hiểu và truyền tải, một thay đổi có thể làm định nghĩa lại cách con người giao tiếp.
Nguồn: The Brighter Side, Digitaltrends



.png "Công an thông báo: Cuộc gọi không nên nghe máy, kết bạn, không tải file gửi qua Zalo, Messenger, SMS")
















