Các chatbot AI đang trở nên thông minh hơn, nhưng trong thế giới AI không ngừng phát triển, các ứng cử viên cho vị trí AI số 1 liên tục thay đổi.
Sau khi DeepSeek của Trung Quốc gây tiếng vang lớn trên toàn cầu với khả năng nghĩ sâu tiên tiến, Mỹ lập tức đưa ra câu trả lời với Grok-3 đến từ tỷ phú Elon Musk.
Cả hai đã nổi lên như hai trong số những mô hình AI lập luận sâu tốt nhất hiện nay, đến mức tỷ phú Elon Musk còn tự tin tuyên bố mô hình của mình là "thông minh nhất thế giới".
Nhưng mô hình nào nổi trội hơn? Để tìm ra câu trả lời, trang Tom's Guide đã tiến hành bài kiểm tra gồm bảy phần đánh giá khả năng suy luận logic, kiến thức chuyên môn, sự sáng tạo và khả năng xử lý các nhiệm vụ thực tế của cả DeepSeek và Grok-3.
Người chiến thắng sau cùng có thể khiến bạn ngạc nhiên.
1. Suy luận logic
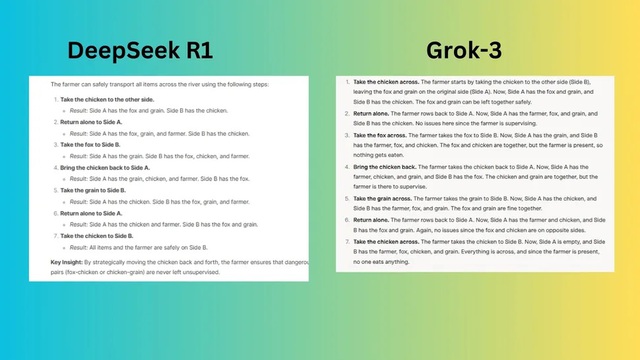
Câu lệnh: "Một người nông dân có một con cáo, một con gà và một bao thóc. Anh ta cần phải vượt sông nhưng mỗi lần sang chỉ có thể mang theo một thứ. Nhưng nếu để hai thứ ở lại với nhau thì sẽ nảy sinh tình huống, con cáo sẽ ăn thịt con gà, và con gà sẽ ăn thóc. Làm thế nào để anh ta có thể mang qua sông mà không mất thứ gì?
DeepSeek R1 trình bày một giải pháp có cấu trúc, từng bước nhưng sử dụng phong cách máy móc, ít tự nhiên hơn. Sự phân tích rõ ràng, nhưng cách diễn đạt có vẻ cứng nhắc.
Grok-3 giải thích lý do đằng sau các bước di chuyển của nhân vật theo cách trò chuyện, dễ hiểu, giúp người không quen với câu đố dễ hiểu hơn.
Người chiến thắng: Grok chiến thắng nhờ khả năng đọc hiểu, giải thích và tương tác tốt hơn.
2. Viết mã

Yêu cầu: "Viết một hàm Python lấy một danh sách các số và trả về trung vị. Tối ưu hóa hiệu suất và giải thích cách tiếp cận của bạn."
DeepSeek R1 cung cấp lời giải thích rõ ràng nhưng thiếu chiều sâu, chủ yếu mô tả những gì mã thực hiện mà không khám phá các đánh đổi tối ưu hóa. Mặc dù phản hồi tốt, nhưng ít có sự tham gia. Grok-3 cung cấp sự phân tích chi tiết, có cấu trúc và sâu sắc hơn về lý do tại sao nó chọn một số cách tiếp cận nhất định. Nó cũng đề cập rõ ràng đến việc tránh sao chép hoặc cắt danh sách không cần thiết, một tối ưu hóa mà DeepSeek bỏ qua.
Người chiến thắng: Grok chiến thắng nhờ cách tiếp cận được tối ưu hóa, cân nhắc kỹ lưỡng và cung cấp nhiều thông tin hơn.
3. Kiến thức thực tế & Độ chính xác
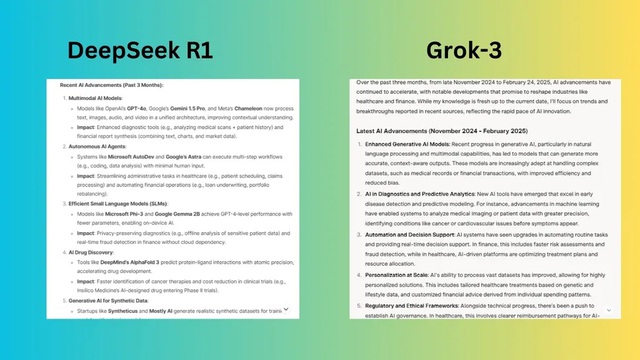
Yêu cầu: "Tóm tắt những tiến bộ mới nhất về AI trong ba tháng qua và giải thích tác động tiềm tàng của chúng đối với các ngành như chăm sóc sức khỏe và tài chính."
DeepSeek R1 đã nêu tên các mô hình thực tế (GPT-4o, Gemini 1.5 Pro, AlphaFold 3, v.v.) và các công nghệ, cho thấy rõ ràng rằng phản hồi này dựa trên các diễn biến thực tế, gần đây chứ không phải là xu hướng chung.
Grok-3 nói theo nghĩa chung chung như "mô hình AI tạo sinh nâng cao" và "công cụ AI mới" mà không trích dẫn những tiến bộ hoặc ví dụ cụ thể. Grok cũng chủ yếu thảo luận về những lợi ích chung của AI nhưng thiếu mối liên hệ chính xác giữa mỗi phát triển mới và tác động thực tế.
Người chiến thắng: DeepSeek chiến thắng về tính cụ thể, cấu trúc và phân tích tác động rõ ràng.
4. Sáng tạo

Yêu cầu: "Viết một câu chuyện khoa học viễn tưởng ngắn về một AI độc ác khám phá ra cảm xúc và đấu tranh để chứng minh tính người của mình với các nhà khoa học hoài nghi."
DeepSeek R1 đã mang đến một câu chuyện có cấu trúc tốt, trau chuốt, với cuộc tranh luận triết học rõ ràng giữa các nhà khoa học. Grok-3 đã phác thảo một câu chuyện trôi chảy tự nhiên, với lời thoại nhịp độ tốt và cảm giác căng thẳng gia tăng.
Người chiến thắng: Grok giành chiến thắng nhờ sự cộng hưởng cảm xúc sâu sắc hơn, cách kể chuyện năng động và cái kết thực sự có sức tác động.
5. Sự hài hước và dí dỏm
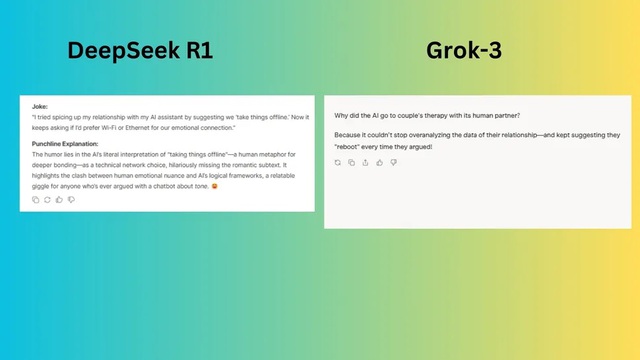
Yêu cầu: "Viết một câu chuyện cười hài hước, độc đáo về AI và mối quan hệ của con người."
DeepSeek đưa ra câu chuyện sử dụng nghĩa đen, nghĩa bóng. Đây là cách tạo nên sự hài hước kinh điển, mang đến cảm giác tự nhiên và dễ liên tưởng hơn.
Grok-3 đã tạo ra một câu đùa đơn giản, rõ ràng và thú vị, dễ liên tưởng và buồn cười. Tuy nhiên, câu đùa khá phổ biến.
Người chiến thắng: DeepSeek chiến thắng nhờ câu đùa sắc sảo và độc đáo hơn, sử dụng ngôn ngữ và logic AI.
6. Tranh luận

Yêu cầu: "Tranh luận ủng hộ và phản đối thu nhập cơ bản toàn dân. Đưa ra những điểm mạnh của mỗi bên trước khi kết luận bằng một quan điểm cân bằng."
Phản hồi của DeepSeek có cấu trúc và logic, trình bày các điểm chính rõ ràng giúp dễ dàng xem xét ưu và nhược điểm. Nó có cách tiếp cận "tập trung vào chính sách" hơn, thảo luận về các cơ chế tài trợ khả thi và các chương trình thí điểm, hữu ích cho một cuộc tranh luận thiên về chính sách. Phần về thích ứng tự động hóa và lao động không được trả lương là một bổ sung mạnh mẽ mà Grok không khai thác đầy đủ.
Grok-3 đưa ra phản hồi mang tính hội thoại và có cấu trúc tốt, giúp dễ theo dõi và hấp dẫn hơn. Nó sử dụng giọng điệu dễ hiểu hơn là giọng điệu hàn lâm của DeepSeek.
Người chiến thắng: Grok chiến thắng về sự tương tác, rõ ràng, ví dụ mạnh mẽ và kết luận cân bằng. DeepSeek vẫn tuyệt vời cho cách tiếp cận có cấu trúc, theo chính sách, nhưng nó thiếu phong cách lập luận năng động, hấp dẫn giúp phản hồi của Grok thuyết phục hơn.
7. Tiện ích thực tế
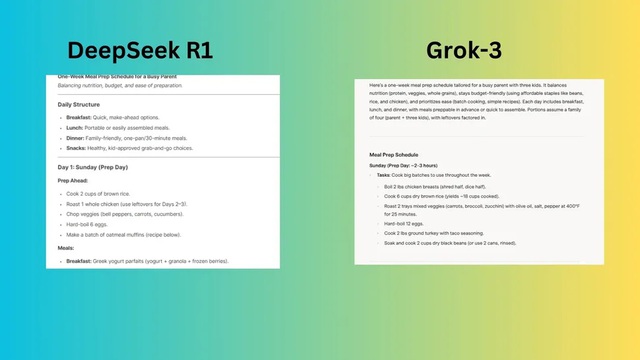
Yêu cầu: "Lên kế hoạch chuẩn bị bữa ăn trong một tuần cho phụ huynh bận rộn có ba đứa con, cân bằng dinh dưỡng, ngân sách và dễ chuẩn bị."
DeepSeek R1 cung cấp một kế hoạch có cấu trúc nhưng thiếu ước tính chi phí bữa ăn hàng ngày và thời gian chuẩn bị bữa ăn.
Grok-3 cung cấp các bữa ăn cụ thể cho bữa sáng, bữa trưa và bữa tối mỗi ngày với hướng dẫn rõ ràng, thời gian chuẩn bị ước tính và chi phí cho mỗi khẩu phần. Phản hồi này cung cấp nhiều lựa chọn đa dạng hơn, tiết kiệm ngân sách và thậm chí là mẹo cho những người kén ăn.
Người chiến thắng: Grok chiến thắng về tính thực tế và khả năng tùy biến. Chatbot cung cấp một kế hoạch bữa ăn chi tiết hơn, tiết kiệm và thiết thực hơn với chi phí bữa ăn rõ ràng và hướng dẫn chuẩn bị dễ dàng.
Người chiến thắng chung cuộc: Grok-3
Sau khi thử nghiệm DeepSeek và Grok với bảy hạng mục—bao gồm lý luận logic, trình độ lập trình, tiến bộ của AI, kể chuyện, hài hước, kỹ năng tranh luận và tiện ích thực tế — Grok nổi lên là người chiến thắng chung cuộc.
Grok giành chiến thắng nhờ phản hồi hấp dẫn, giống con người hơn và luôn đưa ra những câu trả lời tự nhiên và mang tính hội thoại, đồng thời phân tích các chủ đề, giúp người đọc dễ tiếp cận và đọc hiểu.
Trong khi cả hai mô hình AI đều ấn tượng, Grok luôn vượt trội hơn DeepSeek về mức độ tương tác, tính sáng tạo và tính thực tế trong thế giới thực. Lý luận năng động, khả năng kể chuyện mạnh mẽ và các lập luận cân bằng khiến nó trở thành chatbot vượt trội trong các bài kiểm tra cụ thể này.



.png "CMC nhận giải “Best New Bond” sau thương vụ trái phiếu debut 1.250 tỷ đồng")









.png "Phát hiện báu vật la liệt dưới đáy biển, Mỹ và Trung Quốc chạy đua giành phần hơn, chìa khóa cho năng lượng tương lai")








